「コピぺ de 関数」FILE_10
万能過ぎるワイルドカード
今回のキーワードは、ワイルドカードです。
ワイルドカードとは、すべてのパターンに当てはまる文字列のことを指します。
Excel上では「*」(アスタリスク)や「?」(クエスチョンマーク)で表されます。
例えば「*」を使うとどんなことができるのかと言うと、具体例を使って解説します。
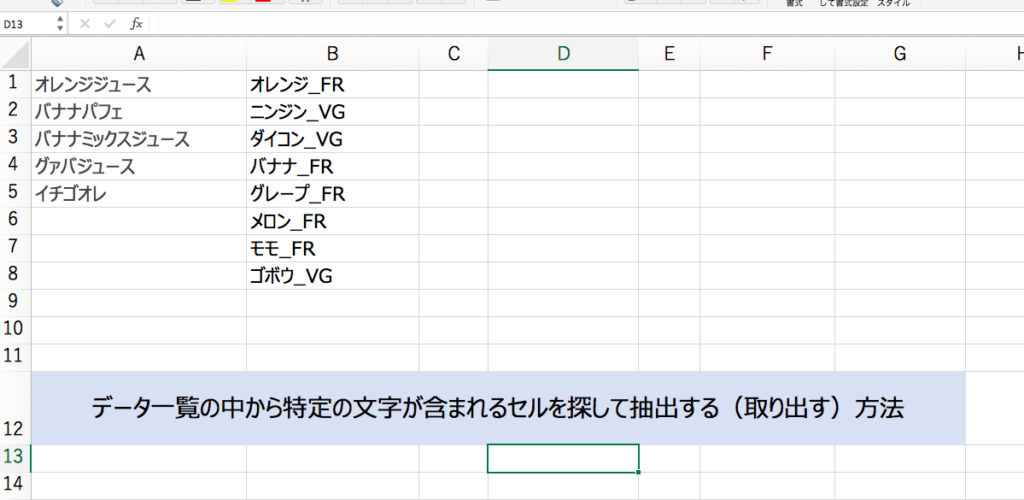
下記のような表があるとします。下記のデータを自身のExcelのA1セルにコピペしてください。
| オレンジジュース |
|---|
| バナナパフェ |
| バナナミックスジュース |
| グァバジュース |
| イチゴオレ |
この一覧の中から、ジュースがつくものは何個あるか調べることができます。
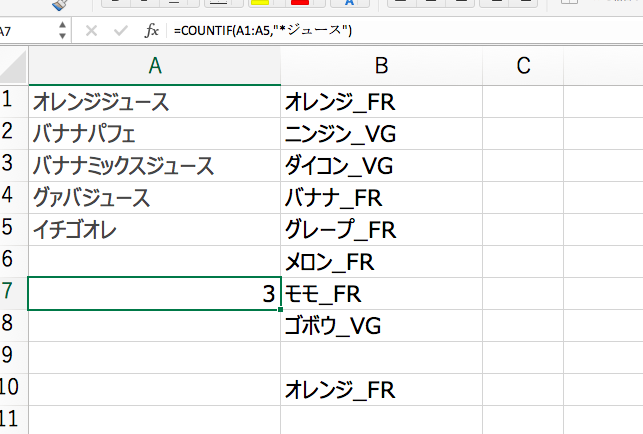
表をコピペしたら、A7セルに下記の数式をコピペしてください。
=COUNTIF(A1:A5,”*ジュース”)
すると結果は3となります。
このように、「*」を使って「何かしらの文字列」プラス特定の文字列のように組み合わせて使うことで、その機能が発揮されます。
「?」を使った場合、「?」一つで1文字分の何かを当てはめることができます。
「201?」という風に使えば、2010〜2019の範囲で調べることができます。
「*」は1文字入れれば、「*」のところには1文字でも100文字でも何かしらの文字列が入っていれば該当することになりますが、「?」は探したい文字列分だけ「?」を入れれば検索する文字数を制限できます。
このワイルドカードの機能を応用して、今回のトピックについて解説していきたいと思います。
データ一覧から条件に一致するデータを取り出す
ワイルドカードを使うことで、部分的に一致するデータを取り出すことができるので、ぜひ試してみてください。
まずはこちらのデータをご自身のExcelのB1セルにコピペしてください。
| オレンジ_FR |
|---|
| ニンジン_VG |
| ダイコン_VG |
| バナナ_FR |
| グレープ_FR |
| メロン_FR |
| モモ_FR |
| ゴボウ_VG |
このデータのように、あるデータベースの中から必要なデータを取り出そうとするとき、大抵の場合はそのデータに規則性があります。
先程の表のデータにもあるように、属性が同じものにはFR(フルーツ)、VG(ベジタブル)といったデータを識別する文字列が入ってたりします。
その識別する文字列とワイルドカードを組み合わせて、データを取り出していきます。
データ一覧の中から、条件に一致するデータを何個も取り出すのは関数を作る際にひと工夫する必要があります。
それは、データに番号をつけてあげることです。(重要)
この説明だけではイメージがつきにくいと思いますので、順を追って説明したいと思います。
データ一覧からデータを取り出すには、工夫が必要
単純な数式を使ってデータを取り出せなくはないですが、一つしか取り出せません。
どういうことかと言いますと、実際にやってみるとわかると思いますので、下記の数式をB10セルにコピペしてみてください。
=INDEX(B1:B8,MATCH(“*FR”,B1:B8,FALSE))
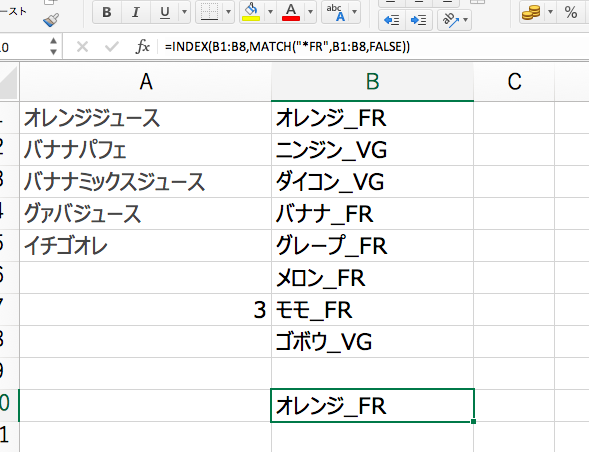
結果として、「オレンジ_FR」になります。
これは、「B1からB8までの範囲で”何かの文字列プラスFR”というデータがあったら、そのデータを取り出す」という動きとなります。
ですので、結果としてFRが含まれている「オレンジ_FR」というデータを取ってきているということになります。
しかし、ここで問題が発生してしまいます。
FRが付いているデータは他にもあるのに、上記の数式では「オレンジ_FR」しか取り出せないということです。
VLOOKUP関数を使っても同じようなことになりますが、数式で同じ条件のデータが見つかった時、「リストの中で該当するデータが複数見つかった時、一番最初に該当したデータを取ってくる」という決まりがあるからです。
ですので、B1セルの「オレンジ_FR」しか取ってくることができません。
よって、他の「バナナ_FR」、「グレープ_FR」、「メロン_FR」、「モモ_FR」のデータを取り出すには工夫を加える必要が出てきます。
そこで、C1セルに下記の数式を加えてください。
=COUNTIF($B$1:B1,”*FR”)
これは「FR」という文字が入ったセルをカウントする数式です。
この数式をずずずいーっとC8セルまでコピーします。
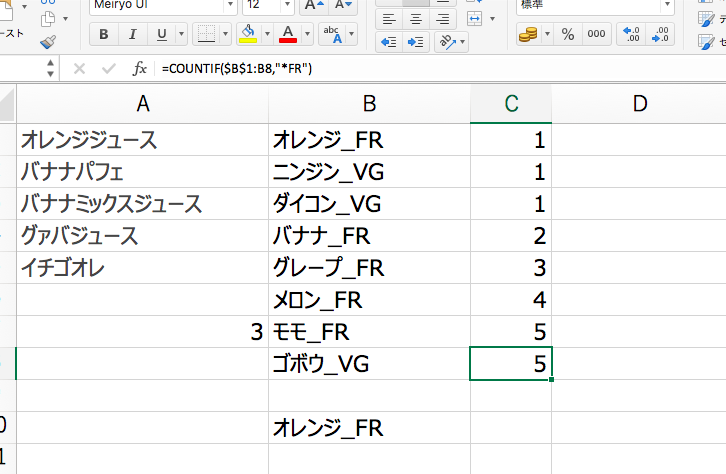
すると、「FR」という文字が入ったセルを見つけるたびに、C列の値は増加していきます。
次に、D1セルに下記の数式をコピペしてください。
=B1&C1
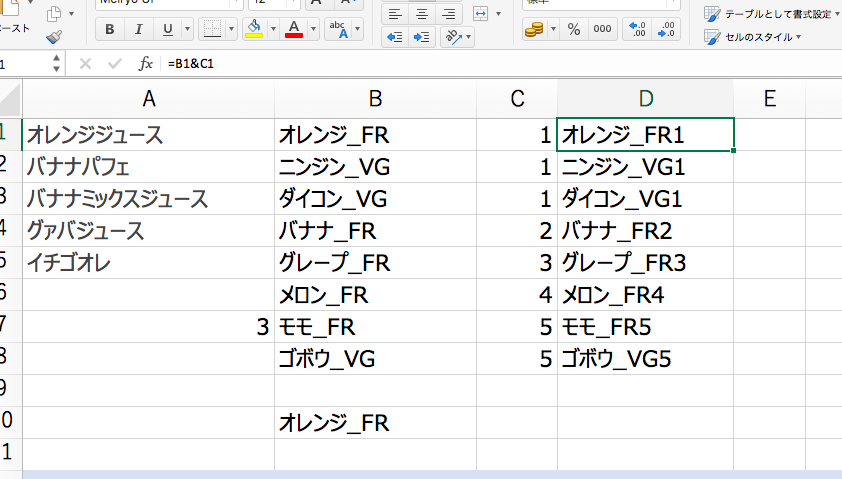
この数式もずずずいーっとD8セルまでコピペします。
ここで注目していただきたいのが「FR」が付いたデータに対して、上から1、2、3、4、5と番号が付いていくということです。
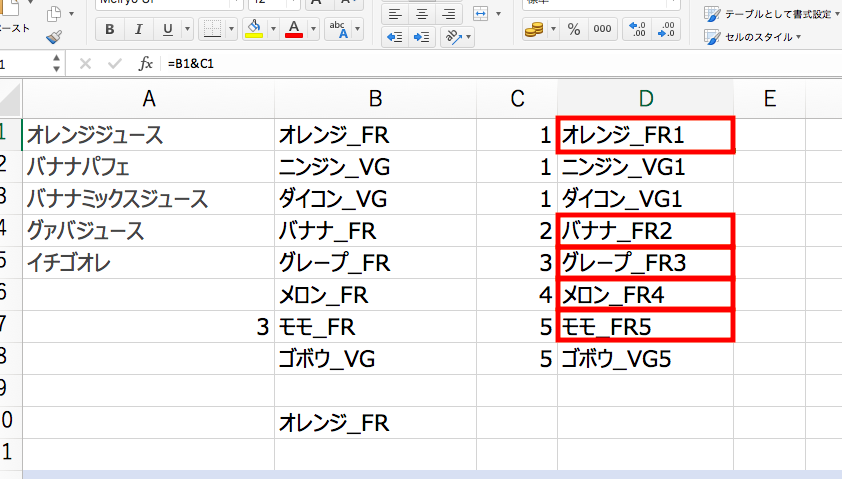
先ほどのC列の数式の結果の値とB列のデータを合体させることで、「FR」が付いたデータに固有の番号を付け加えることができます。
簡単にいえば、「なんとかFR」に対して、上から番号をふってあげたという訳です。
そして、F1セルに下記の数式をコピペしてみましょう。
=INDEX($B$1:$B$8,MATCH(“*FR”&”1”,$D$1:$D$8,FALSE))
ちょっと長い数式ですが、動きとしては「D1からD8セルの中で”なんとかFR1”というデータを探して上から何番目を調べ、B列の同じ行のデータを取ってくる。」という感じになります。
F1セルの数式をずずずいーっとF8セルまでコピーすると、
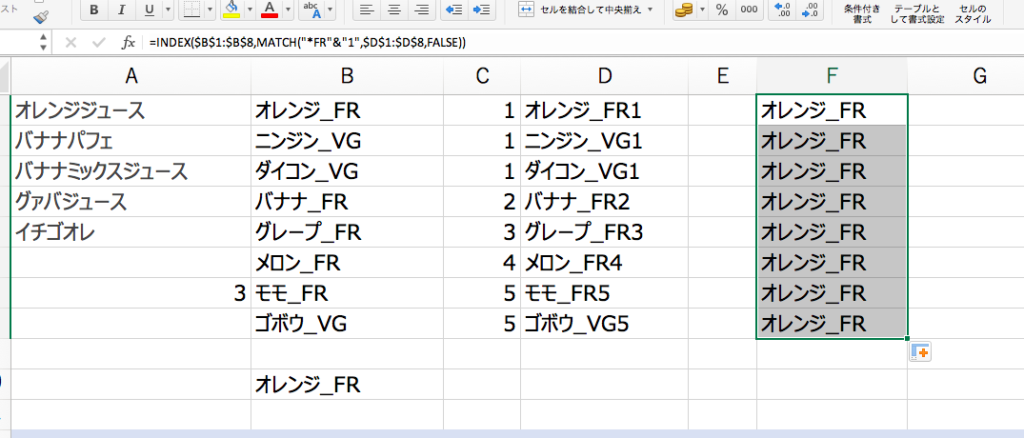
全部「オレンジ_FR」になってしまいました。
F2セル以降は、数式内の”1”を”2”、”3”、”4”、、、と手作業で修正していく必要があります。
これは、D列のデータを探すときに、「なんとかFR1」、「なんとかFR2」、「なんとかFR3」、、、と番号をつけたデータを探すために必要という訳です。
もし手作業で数字を書き換えていくのが面倒でしたら、E列に上から1、2、3、、、、と用意します。
その数字を拾いながら計算していく下記の数式であれば、手作業で数字を変えていく必要はありません。
=INDEX($B$1:$B$8,MATCH(“*FR”&E1,$D$1:$D$8,FALSE))
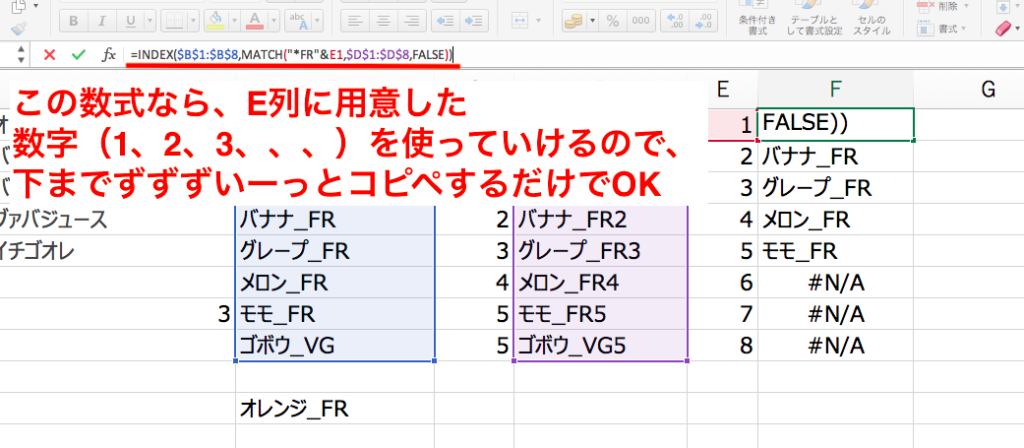
手作業で数式を修正していくなら、このようになります。
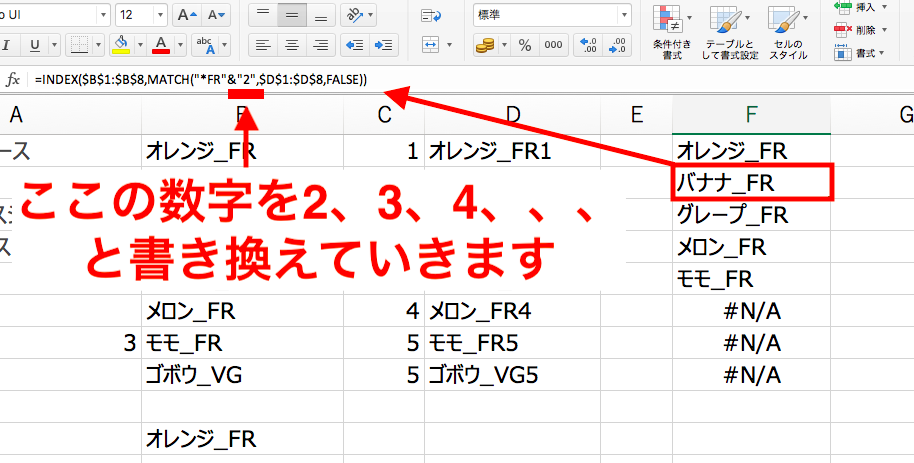
どちらの方法でやったにせよ、途中まではいいですがF6セル以下はエラーになっていますね。
これは、「なんとかFR6」以降のデータが見つからないという意味と捉えてください。
つまり、B2からB8までのセルには5つしかFRのデータはないということです。
このエラーを解消するには、「数式がエラーの時は空白にする」という関数を加えてやります。
IFERROR関数を加えた下記の数式をG1セルにコピペしてください。
=IFERROR(INDEX($B$1:$B$8,MATCH(“*FR”&E1,$D$1:$D$8,FALSE)),””)
そのあと、ずずずいーっとG8セルまでコピーしていけばOKです。
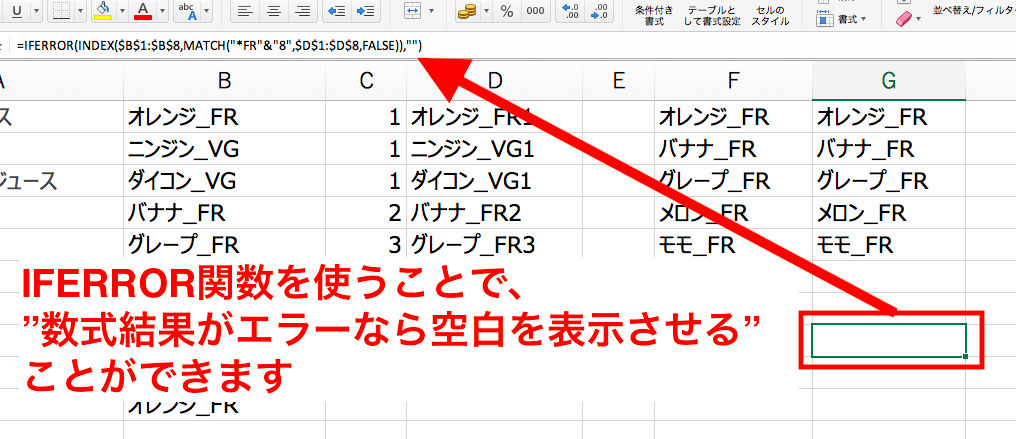
これで完成です!
「なんとかFR」の一覧が完成しました。
データ一覧から特定の文字が含まれるデータを取り出すのはいくつかのステップが必要になりますが、抽出することができます。
必ずやどこかで使えるテクニックだと思いますので、ぜひ試してみて覚えてくださいね!
今回使った数式
COUNTIF関数・・・条件に合致したデータの数をカウントする
INDEX関数・・・指定した行の値を取ってくる
MATCH関数・・・指定したデータが何行目にあるか調べる
IFERROR関数・・・数式結果がエラーかどうか判定する
次回は、リスト内の条件を満たす行の値を抽出する(DGET)方法を解説いたします!