「コピぺ de 関数」FILE_16
今回は、2022年にコメントいただいた方のリクエストにお応えしたいと思い、調べた方法を書いていきたいと思います!
セルの中に入っている文字列を抽出する方法です。
こちらの記事で似たような解決法を載せておりますが、今回はもう少し複雑な方法になります。
データの中から文字列を取り出す色んな方法(RIGHT,LEFT,MID,FIND関数) Excel_02
今回ご紹介する方法は、一つのセルに空白やカンマ区切りでデータが入っていて、最後の区切り以降の文字列を抜き出したいという場合に使えるかなと思います。
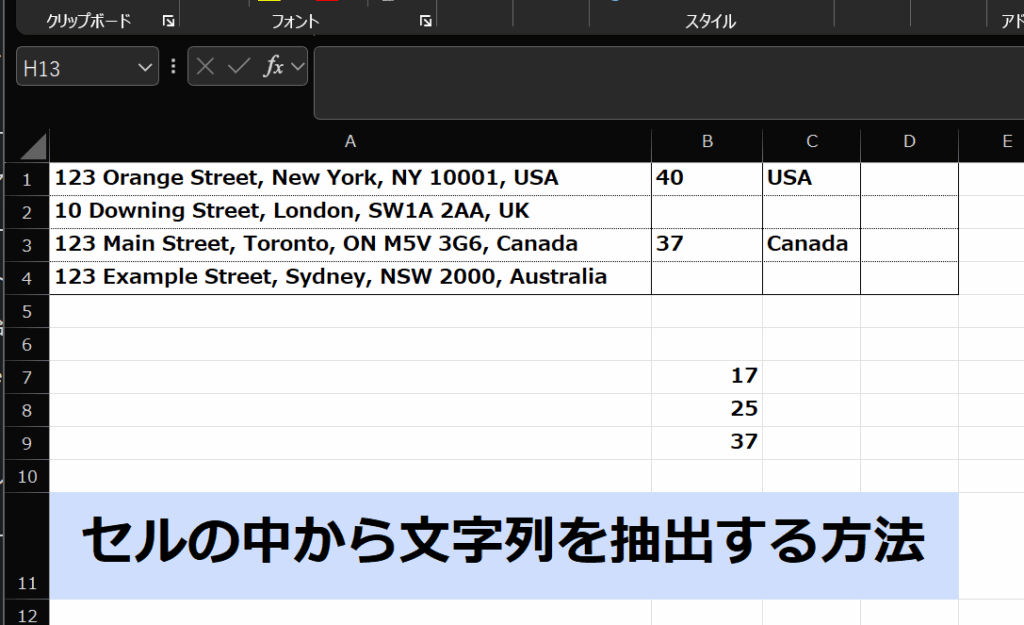
まずはいつものように、A1セルに下記のデータを貼り付けてください。
| 123 Orange Street, New York, NY 10001, USA | ||
|---|---|---|
| 10 Downing Street, London, SW1A 2AA, UK | ||
| 123 Main Street, Toronto, ON M5V 3G6, Canada | ||
| 123 Example Street, Sydney, NSW 2000, Australia |
2つの方法をそれぞれ書いていきます!
substitute関数を使ったやり方
A1セルのデータには、データの切れ目に、カンマと空白が入っています。
関数の動きとしては、「(A1セル内の文字列の合計)から、(セルの中の空白を除いた文字列の合計)を引いて、その結果(例では”3″)を元に、3個目の空白を●に置き換え、その●までの文字数を返す」という感じです。
では、早速下記の数式を、B1セルに入れてください。
=FIND(“●”, SUBSTITUTE(A1, ” “, “●”, LEN(A1) – LEN(SUBSTITUTE(A1, ” “, “”))))+1
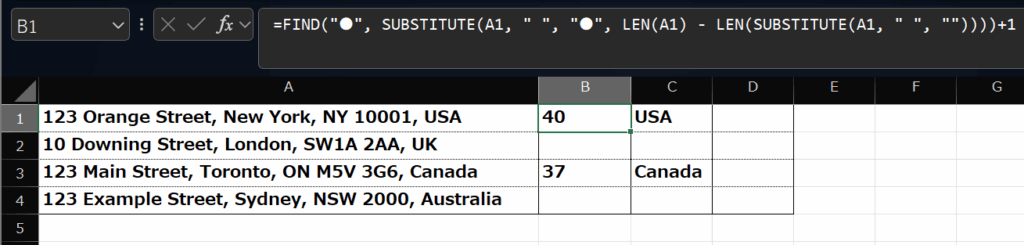
すると、40という数字が結果として出てきます。
これは、3回目の空白の手前までの文字数を表します。
数式の最後の「+1」は文字を抜き出す際に、空白を含めないよう調整するための数です。
では次に、下記の数式をC1セルに入れてください。
=MID(A1,B1,20)
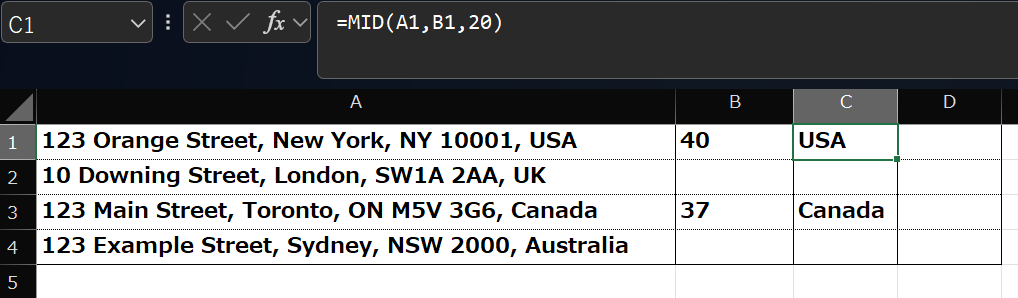
すると、”USA”が結果として出てきます。
さきほどの「+1」がないと、” USA”になってしまいます。
数式内の”20″というのは、何文字抽出するかの数なので、適当な数でOKです。
find関数を使ったやり方
こっちの関数は、「〇番目のカンマ以降の文字列を抜き出す」という動きになります。
〇は自身で決めることになります。(例では3番目としてます)
とりあえず目的を果たす関数の動きを見てみましょう。
下記の関数を、B3セルにコピペしてください。
=FIND(“,”, A3, FIND(“,”, A3, FIND(“,”, A3) + 1) + 1)
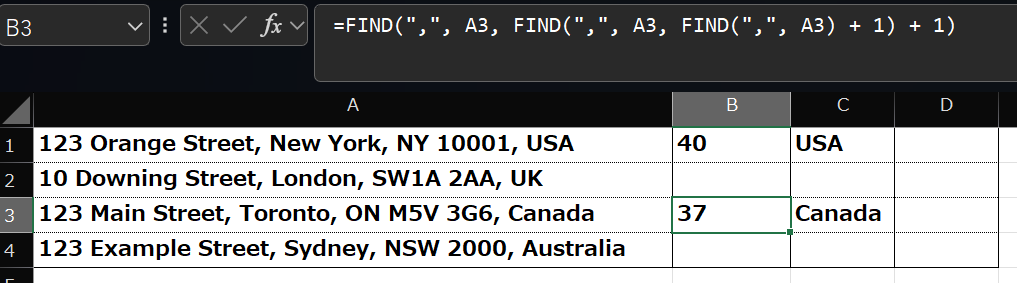
結果は、37となって、”Canada” の直前にあるカンマまでの文字数を表してます。
次に、C3セルに、下記の数式をコピペしてください。
=MID(A3,B3+2,20)
これで、”Canada”を抽出することができました。
今回は3つ目のカンマ以降の文字列をとるため、上記の数式になってますが、アレンジする場合はこちらを参考にしてください!

「FIND(“,”, A3) + 1」という数式をどんどんネスト化させていくことで、〇個目の△の位置を取得して、それ以降の文字列を抜き出す、というやり方になります。
上記の関数の動きとしては、「セル内の文字の中から、”,”までの文字数を返す」です。
これをネスト化させていくとはどういうことなのか?
find関数の動きは、「=FIND(検索文字列,対象,開始位置)」となっていて、3つ目の引数である開始位置の数(=検索した文字列までの文字数)を増やしていくことで、1個目の〇から次の〇までの文字数、2個目の〇から次の〇までの文字数、、、を取得することできるというわけです。
今回は、セル内の文字列の最後のデータを抜き出す方法になりますが、セル内の文字列の真ん中あたりに入ってるデータの抽出したい!ってこともあると思います。
その場合は、こちらの記事のやり方が良いと思いますので、見てみてください♪
セル内の特定の位置にある文字列を抽出する方法 Excel_17